Models#
AdONE#
- class pygod.models.AdONE(Adversarial Outlier Aware Attributed Network Embedding)[source]#
Bases:
BaseDetectorAdONE consist of an attribute autoencoder and a structure autoencoder. It estimates five loss to optimize the model, including an attribute proximity loss, an attribute homophily loss, a structure proximity loss, a structure homophily loss, and an alignment loss. It calculates three outlier score, and averages them as an overall score.
See [BVM20] for details.
- Parameters
hid_dim (int, optional) – Hidden dimension for both attribute autoencoder and structure autoencoder. Default:
0.num_layers (int, optional) – Total number of layers in model. A half (ceil) of the layers are for the encoder, the other half (floor) of the layers are for decoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.a1 (float, optional) – Loss balance weight for structure proximity. Default:
0.2.a2 (float, optional) – Loss balance weight for structure homophily. Default:
0.2.a3 (float, optional) – Loss balance weight for attribute proximity. Default:
0.2.a4 (float, optional) – Loss balance weight for attribute proximity. Default:
0.2.a5 (float, optional) – Loss balance weight for alignment. Default:
0.2.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
5.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import AdONE >>> model = AdONE() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
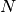 .
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
AnomalyDAE#
- class pygod.models.AnomalyDAE(embed_dim=8, out_dim=4, dropout=0.2, weight_decay=1e-05, act=<function relu>, alpha=0.5, theta=1.01, eta=1.01, contamination=0.1, lr=0.004, epoch=5, gpu=0, batch_size=0, num_neigh=-1, verbose=False)[source]#
Bases:
BaseDetectorAnomalyDAE (Dual autoencoder for anomaly detection on attributed networks): AnomalyDAE is an anomaly detector that. consists of a structure autoencoder and an attribute autoencoder to learn both node embedding and attribute embedding jointly in latent space. The structural autoencoer uses Graph Attention layers. The reconstruction mean square error of the decoders are defined as structure anamoly score and attribute anomaly score, respectively, with two additional penalties on the reconstructed adj matrix and node attributes (force entries to be nonzero).
See: cite ‘fan2020anomalydae’ for details.
- Parameters
embed_dim (int, optional) – Hidden dimension of model. Defaults: 8`.
out_dim (int, optional) – Dimension of the reduced representation after passing through the structure autoencoder and attribute autoencoder. Defaults:
4.dropout (float, optional) – Dropout rate. Defaults:
0.2.weight_decay (float, optional) – Weight decay (L2 penalty). Defaults:
1e-5.act (callable activation function or None, optional) – Activation function if not None. Defaults:
torch.nn.functional.relu.alpha (float, optional) – loss balance weight for attribute and structure. Defaults:
0.5.theta (float, optional) – greater than 1, impose penalty to the reconstruction error of the non-zero elements in the adjacency matrix Defaults:
1.01eta (float, optional) – greater than 1, imporse penalty to the reconstruction error of the non-zero elements in the node attributes Defaults:
1.01contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Defaults:
0.1.lr (float, optional) – Learning rate. Defaults:
0.004.epoch (int, optional) – Maximum number of training epoch. Defaults:
5.gpu (int) – GPU Index, -1 for using CPU. Defaults:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.verbose (bool) – Verbosity mode. Turn on to print out log information. Defaults:
False.
Examples
>>> from pygod.models import AnomalyDAE >>> model = AnomalyDAE() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score of X using the fitted detector. The anomaly score of an input sample is computed based on different detector algorithms. For consistency, outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
anomaly_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
CoLA#
- class pygod.models.CoLA(lr=0.001, epoch=10, embedding_dim=64, negsamp_ratio=1, readout='avg', weight_decay=0.0, batch_size=0, subgraph_size=4, contamination=0.1, gpu=0, verbose=False)[source]#
Bases:
BaseDetectorCoLA (Anomaly Detection on Attributed Networks via Contrastive Self-Supervised Learning) CoLA is a contrastive self-supervised learning-based method for graph anomaly detection. (beta)
- Parameters
lr (float, optional) – Learning rate. Default:
1e-3.epoch (int, optional) – Maximum number of training epoch. Default:
10.embedding_dim (int, optional) – The node embedding dimension obtained by the GCN module of CoLA. Default:
64.negsamp_ratio (int, optional) – Number of negative samples for each instance used by the contrastive learning module. Default:
1.readout (str, optional) – The readout layer type used by CoLA model. Default:
avg.weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.subgraph_size (int, optional) – Number of nodes in the subgraph sampled by random walk. Default:
4.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.gpu (int, optional) – GPU Index, -1 for using CPU. Default:
0.verbose (bool, optional) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import CoLA >>> model = CoLA() >>> model.fit(data) >>> prediction = model.predict(data)
- decision_function(G, rounds=10)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
rounds (int, optional) – Number of rounds to generate the decision score. Default:
10.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
CONAD#
- class pygod.models.CONAD(Contrastive Attributed Network Anomaly Detection)[source]#
Bases:
BaseDetectorCONAD is an anomaly detector consisting of a shared graph convolutional encoder, a structure reconstruction decoder, and an attribute reconstruction decoder. The model is trained with both contrastive loss and structure/attribute reconstruction loss. The reconstruction mean square error of the decoders are defined as structure anomaly score and attribute anomaly score, respectively.
See [XHZ+22] for details.
- Parameters
hid_dim (int, optional) – Hidden dimension of model. Default:
0.num_layers (int, optional) – Total number of layers in model. A half (ceil) of the layers are for the encoder, the other half (floor) of the layers are for decoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.alpha (float, optional) – Loss balance weight for attribute and structure. Default:
0.5.eta (float, optional) – Loss balance weight for contrastive and reconstruction. Default:
0.5.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
5.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.r (float, optional) – The rate of augmented anomalies. Default:
.2.m (int, optional) – For densely connected nodes, the number of edges to add. Default:
50.k (int, optional) – same as
kinutils.outlier_generator.gen_attribute_outliers. Default:50.f (int, optional) – For disproportionate nodes, the scale factor applied on their attribute value. Default:
10.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import CONAD >>> model = CONAD() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
DOMINANT#
- class pygod.models.DOMINANT(Deep Anomaly Detection on Attributed Networks)[source]#
Bases:
BaseDetectorDOMINANT is an anomaly detector consisting of a shared graph convolutional encoder, a structure reconstruction decoder, and an attribute reconstruction decoder. The reconstruction mean square error of the decoders are defined as structure anomaly score and attribute anomaly score, respectively.
See [DLBL19] for details.
- Parameters
hid_dim (int, optional) – Hidden dimension of model. Default:
0.num_layers (int, optional) – Total number of layers in model. A half (ceil) of the layers are for the encoder, the other half (floor) of the layers are for decoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.alpha (float, optional) – Loss balance weight for attribute and structure. Default:
0.5.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
5.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import DOMINANT >>> model = DOMINANT() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
DONE#
- class pygod.models.DONE(Deep Outlier Aware Attributed Network Embedding)[source]#
Bases:
BaseDetectorDONE consist of an attribute autoencoder and a structure autoencoder. It estimates five loss to optimize the model, including an attribute proximity loss, an attribute homophily loss, a structure proximity loss, a structure homophily loss, and a combination loss. It calculates three outlier score, and averages them as an overall score.
See [BVM20] for details.
- Parameters
hid_dim (int, optional) – Hidden dimension for both attribute autoencoder and structure autoencoder. Default:
0.num_layers (int, optional) – Total number of layers in model. A half (ceil) of the layers are for the encoder, the other half (floor) of the layers are for decoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.a1 (float, optional) – Loss balance weight for structure proximity. Default:
0.2.a2 (float, optional) – Loss balance weight for structure homophily. Default:
0.2.a3 (float, optional) – Loss balance weight for attribute proximity. Default:
0.2.a4 (float, optional) – Loss balance weight for attribute proximity. Default:
0.2.a5 (float, optional) – Loss balance weight for combination. Default:
0.2.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
5.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import DONE >>> model = DONE() >>> model.fit(data) >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
GAAN#
- class pygod.models.GAAN(Generative Adversarial Attributed Network Anomaly Detection)[source]#
Bases:
BaseDetectorGAAN is a generative adversarial attribute network anomaly detection framework, including a generator module, an encoder module, a discriminator module, and uses anomaly evaluation measures that consider sample reconstruction error and real sample recognition confidence to make predictions.
See [CLW+20] for details.
- Parameters
noise_dim (int, optional) – Dimension of the Gaussian random noise. Defaults:
32.latent_dim (int, optional) – Dimension of the latent space. Defaults:
32.hid_dim1 (int, optional) – Hidden dimension of MLP later 1. Defaults:
32.hid_dim2 (int, optional) – Hidden dimension of MLP later 2. Defaults:
64.hid_dim3 (int, optional) – Hidden dimension of MLP later 3. Defaults:
128.num_layers (int, optional) – Total number of layers in model. Defaults:
3.dropout (float, optional) – Dropout rate. Defaults:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Defaults:
0..act (callable activation function or None, optional) – Activation function if not None. Defaults:
torch.nn.functional.relu.alpha (float, optional) – loss balance weight for attribute and structure. Defaults:
0.2.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Defaults:
0.05.lr (float, optional) – Learning rate. Defaults:
0.005.epoch (int, optional) – Maximum number of training epoch. Defaults:
10.gpu (int) – GPU Index, -1 for using CPU. Defaults:
-1.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.verbose (bool) – Verbosity mode. Turn on to print out log information. Defaults:
False.
Examples
>>> from pygod.models import GAAN >>> model = GAAN() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
GCNAE#
- class pygod.models.GCNAE(hid_dim=64, num_layers=4, dropout=0.3, weight_decay=0.0, act=<function relu>, contamination=0.1, lr=0.005, epoch=100, gpu=0, batch_size=0, num_neigh=-1, verbose=False)[source]#
Bases:
BaseDetectorVanila Graph Convolutional Networks Autoencoder
See [YZY+21] for details.
- Parameters
hid_dim (int, optional) – Hidden dimension of model. Default:
0.num_layers (int, optional) – Total number of layers in autoencoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
100.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import GCNAE >>> model = GCNAE() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
GUIDE#
- class pygod.models.GUIDE(a_hid=32, s_hid=4, num_layers=4, dropout=0.3, weight_decay=0.0, act=<function relu>, alpha=0.1, contamination=0.1, lr=0.001, epoch=10, gpu=0, batch_size=0, num_neigh=-1, graphlet_size=4, selected_motif=True, cache_dir=None, verbose=False)[source]#
Bases:
BaseDetectorGUIDE (Higher-order Structure based Anomaly Detection on Attributed Networks) GUIDE is an anomaly detector consisting of an attribute graph convolutional autoencoder, and a structure graph attentive autoencoder (not same as the graph attention networks). Instead of adjacency matrix, node motif degree (graphlet degree is used in this implementation by default) is used as input of structure autoencoder. The reconstruction mean square error of the autoencoders are defined as structure anomaly score and attribute anomaly score, respectively.
Note: The calculation of node motif degree in preprocesing has high time complexity. It may take longer than you expect.
See [YZY+21] for details.
- Parameters
a_hid (int, optional) – Hidden dimension for attribute autoencoder. Default:
32.s_hid (int, optional) – Hidden dimension for structure autoencoder. Default:
4.num_layers (int, optional) – Total number of layers in autoencoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.alpha (float, optional) – Loss balance weight for attribute and structure. Default:
0.5.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
10.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.graphlet_size (int) – The maximum graphlet size used to compute structure input. Default:
4.selected_motif (bool) – Use selected motifs which are defined in the original paper. Default:
True.cache_dir (str) – The directory for the node motif degree caching. Default:
None.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import GUIDE >>> model = GUIDE() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
MLPAE#
- class pygod.models.MLPAE(hid_dim=64, num_layers=4, dropout=0.3, weight_decay=0.0, act=<function relu>, contamination=0.1, lr=0.005, epoch=5, gpu=0, batch_size=0, verbose=False)[source]#
Bases:
BaseDetectorVanila Multilayer Perceptron Autoencoder
See [YZY+21] for details.
- Parameters
hid_dim (int, optional) – Hidden dimension of model. Default:
0.num_layers (int, optional) – Total number of layers in autoencoders. Default:
4.dropout (float, optional) – Dropout rate. Default:
0..weight_decay (float, optional) – Weight decay (L2 penalty). Default:
0..act (callable activation function or None, optional) – Activation function if not None. Default:
torch.nn.functional.relu.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.lr (float, optional) – Learning rate. Default:
0.004.epoch (int, optional) – Maximum number of training epoch. Default:
5.gpu (int) – GPU Index, -1 for using CPU. Default:
0.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import MLPAE >>> model = MLPAE() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outlier_scores – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
OCGNN#
- class pygod.models.OCGNN(n_hidden=256, n_layers=4, contamination=0.1, dropout=0.3, lr=0.005, weight_decay=0, eps=0.001, nu=0.5, gpu=0, epoch=5, warmup_epoch=2, verbose=False, act=<function relu>, batch_size=0, num_neigh=-1)[source]#
Bases:
BaseDetectorOCGNN (One-Class Graph Neural Networks for Anomaly Detection in Attributed Networks): OCGNN is an anomaly detector that measures the distance of anomaly to the centroid, in the similar fashion to the support vector machine, but in the embedding space after feeding towards several layers of GCN.
See [WJD+21] for details.
- Parameters
n_hidden (int, optional) – Hidden dimension of model. Defaults: 256`.
n_layers (int, optional) – Dimensions of underlying GCN. Defaults:
4.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.dropout (float, optional) – Dropout rate. Defaults:
0.3.weight_decay (float, optional) – Weight decay (L2 penalty). Defaults:
0..act (callable activation function or None, optional) – Activation function if not None. Defaults:
torch.nn.functional.relu.eps (float, optional) – A small valid number for determining the center and make sure it does not collapse to 0. Defaults:
0.001.nu (float, optional) – Regularization parameter. Defaults:
0.5lr (float, optional) – Learning rate. Defaults:
0.005.epoch (int, optional) – Maximum number of training epoch. Defaults:
5.warmup_epoch (int, optional) – Number of epochs to update radius and center in the beginning of training. Defaults:
2.gpu (int) – GPU Index, -1 for using CPU. Defaults:
0.verbose (bool) – Verbosity mode. Turn on to print out log information. Defaults:
False.batch_size (int, optional) – Minibatch size, 0 for full batch training. Default:
0.num_neigh (int, optional) – Number of neighbors in sampling, -1 for all neighbors. Default:
-1.
Examples
>>> from pygod.models import AnomalyDAE >>> model = OCGNN() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score of X using the fitted detector. The anomaly score of an input sample is computed based on distance to the centroid and measurement within the radius :param G: The input data. :type G: PyTorch Geometric Data instance (torch_geometric.data.Data)
- Returns
anomaly_scores – The anomaly score of the input samples of shape (n_samples,).
- Return type
numpy.array
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
ONE#
- class pygod.models.ONE(Outlier Aware Network Embedding for Attributed Networks)[source]#
Bases:
BaseDetectorReference: <https://arxiv.org/pdf/1811.07609.pdf>
See [BLM19] for details.
- Parameters
K (int, optional) – Every vertex is a K dimensional vector, K < min(N, D). Default:
36.iter (int, optional) – Number of outer Iterations for optimization. Default:
5.contamination (float, optional) – Valid in (0., 0.5). The proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. Default:
0.1.verbose (bool) – Verbosity mode. Turn on to print out log information. Default:
False.
Examples
>>> from pygod.models import ONE >>> model = ONE() >>> model.fit(data) # PyG graph data object >>> prediction = model.predict(data)
- decision_function(G)[source]#
Predict raw anomaly score using the fitted detector. Outliers are assigned with larger anomaly scores.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input data.
- Returns
outl2 – The anomaly score of shape
.- Return type
numpy.ndarray
- fit(G, y_true=None)[source]#
Fit detector with input data.
- Parameters
G (torch_geometric.data.Data) – The input data.
y_true (numpy.ndarray, optional) – The optional outlier ground truth labels used to monitor the training progress. They are not used to optimize the unsupervised model. Default:
None.
- Returns
self – Fitted estimator.
- Return type
- get_params(deep=True)#
Get parameters for this estimator. See sklearn.base.BaseEstimator for more information.
- Parameters
deep (bool, optional) – If True, will return the parameters for this estimator and contained sub-objects that are estimators. Default:
`True`.- Returns
params – Parameter names mapped to their values.
- Return type
mapping of string to any
- predict(G, return_confidence=False)#
Predict if a particular sample is an outlier or not.
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
outlier_labels (numpy array of shape (n_samples,)) – For each observation, tells whether or not it should be considered as an outlier according to the fitted model. 0 stands for inliers and 1 for outliers.
confidence (numpy array of shape (n_samples,).) – Only if return_confidence is set to True.
- predict_confidence(G)#
Predict the model’s confidence in making the same prediction under slightly different training sets. See [PVD20].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
- Returns
confidence – For each observation, tells how consistently the model would make the same prediction if the training set was perturbed. Return a probability, ranging in [0,1].
- Return type
numpy array of shape (n_samples,)
- predict_proba(G, method='linear', return_confidence=False)#
Predict the probability of a sample being outlier. Two approaches are possible:
simply use Min-max conversion to linearly transform the outlier scores into the range of [0,1]. The model must be fitted first.
use unifying scores, see [KKSZ11].
- Parameters
G (PyTorch Geometric Data instance (torch_geometric.data.Data)) – The input graph.
method (str, optional (default='linear')) – probability conversion method. It must be one of ‘linear’ or ‘unify’.
return_confidence (boolean, optional(default=False)) – If True, also return the confidence of prediction.
- Returns
outlier_probability – For each observation, tells whether it should be considered as an outlier according to the fitted model. Return the outlier probability, ranging in [0,1]. Note it depends on the number of classes, which is by default 2 classes ([proba of normal, proba of outliers]).
- Return type
numpy array of shape (n_samples, n_classes)
- set_params(**params)#
Set the parameters of this estimator. The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object. See sklearn.base.BaseEstimator for more information.- Returns
self
- Return type
Reference#
- BLM19
Sambaran Bandyopadhyay, N Lokesh, and M Narasimha Murty. Outlier aware network embedding for attributed networks. In Proceedings of the AAAI conference on artificial intelligence, volume 33, 12–19. 2019.
- BVM20(1,2)
Sambaran Bandyopadhyay, Saley Vishal Vivek, and MN Murty. Outlier resistant unsupervised deep architectures for attributed network embedding. In Proceedings of the 13th International Conference on Web Search and Data Mining, 25–33. 2020.
- CCL+21
Lei Cai, Zhengzhang Chen, Chen Luo, Jiaping Gui, Jingchao Ni, Ding Li, and Haifeng Chen. Structural temporal graph neural networks for anomaly detection in dynamic graphs. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 3747–3756. 2021.
- CLW+20
Zhenxing Chen, Bo Liu, Meiqing Wang, Peng Dai, Jun Lv, and Liefeng Bo. Generative adversarial attributed network anomaly detection. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 1989–1992. 2020.
- DLBL19
Kaize Ding, Jundong Li, Rohit Bhanushali, and Huan Liu. Deep anomaly detection on attributed networks. In Proceedings of the 2019 SIAM International Conference on Data Mining, 594–602. SIAM, 2019.
- DLS+20
Yingtong Dou, Zhiwei Liu, Li Sun, Yutong Deng, Hao Peng, and Philip S Yu. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 315–324. 2020.
- KKSZ11(1,2,3,4,5,6,7,8,9,10,11,12)
Hans-Peter Kriegel, Peer Kroger, Erich Schubert, and Arthur Zimek. Interpreting and unifying outlier scores. In Proceedings of the 2011 SIAM International Conference on Data Mining, 13–24. SIAM, 2011.
- LDZ+22
Kay Liu, Yingtong Dou, Yue Zhao, Xueying Ding, Xiyang Hu, Ruitong Zhang, Kaize Ding, Canyu Chen, Hao Peng, Kai Shu, George H. Chen, Zhihao Jia, and Philip S. Yu. Pygod: a python library for graph outlier detection. arXiv preprint arXiv:2204.12095, 2022.
- PVD20(1,2,3,4,5,6,7,8,9,10,11,12)
Lorenzo Perini, Vincent Vercruyssen, and Jesse Davis. Quantifying the confidence of anomaly detectors in their example-wise predictions. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 227–243. Springer, 2020.
- WJD+21
Xuhong Wang, Baihong Jin, Ying Du, Ping Cui, Yingshui Tan, and Yupu Yang. One-class graph neural networks for anomaly detection in attributed networks. Neural computing and applications, 33(18):12073–12085, 2021.
- XHZ+22
Zhiming Xu, Xiao Huang, Yue Zhao, Yushun Dong, and Jundong Li. Contrastive attributed network anomaly detection with data augmentation. In Pacific-Asian Conference on Knowledge Discovery and Data Mining (PAKDD). 2022.
- YZY+21(1,2,3)
Xu Yuan, Na Zhou, Shuo Yu, Huafei Huang, Zhikui Chen, and Feng Xia. Higher-order structure based anomaly detection on attributed networks. In 2021 IEEE International Conference on Big Data (Big Data), 2691–2700. IEEE, 2021.